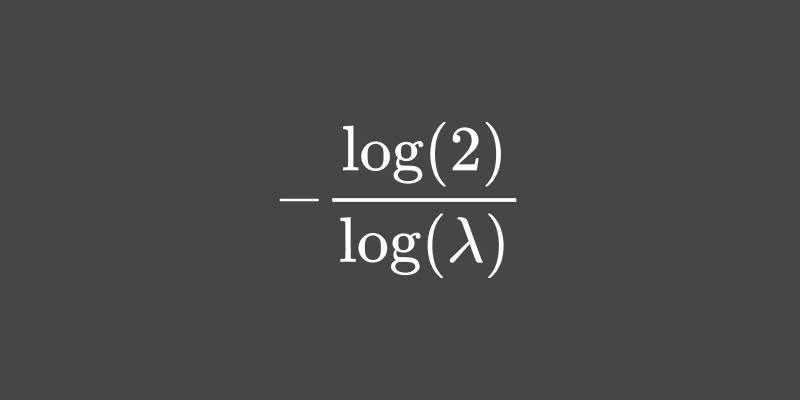Fast Gaussian Kernel fit for Support Vector Regression
Support vector regression models transform input vectors into a high number of dimensions where the regression problem becomes linear. This new space is defined by a kernel function. A major drawback of these models is that they are slow to fit the kernel parameters. Here I develop an algorithm to quickly fit the Gaussian kernel’s bandwidth parameter. This algorithm is fast, robust on some datasets, and has a similar fit to slower and more exhaustive methods.